
Flexway Tablespace-Engine vs. MySQL vs. MariaDB vs. AWS Aurora (MySQL compatible)
To explain why it was decided to create Flexway Tablespace-Engine instead of using well-known existing solutions, performance metrics have been collected to demonstrate how efficient it is compared to established solutions such as MySQL, MariaDB, and AWS Aurora (MySQL-compatible).
This article outlines our straightforward yet practical benchmarking approach, detailing the datasets used and the results obtained.
Throughout the tests regularly performed, performance measurements have consistently shown promising results, suggesting the project was headed in the right direction. However, none of the Flexway components are today in a stable version as development is still running.
As the project progresses, it can now offer more consistent and accurate metrics that better reflect real-world conditions.
Lastly, and perhaps most importantly, the results presented here may seem surprising. They are easily reproducible and verifiable, as this post includes detailed information on the lab setup, data sources, and queries used. All of these elements are fully transparent and available as usable material (Coming soon) to anyone wishing to validate the findings.
Lab Environment
Infrastructure Overview
The benchmark environment is set up on AWS for simplicity. It includes a VPN gateway, 1 Server EC2-instance for the tested database engine applications, 1 EC2-instance for the client application to run MySQL/MariaDB client with AWS Aurora. For AWS Aurora, the RDS/Serverless (MySQL compatible) service is used.
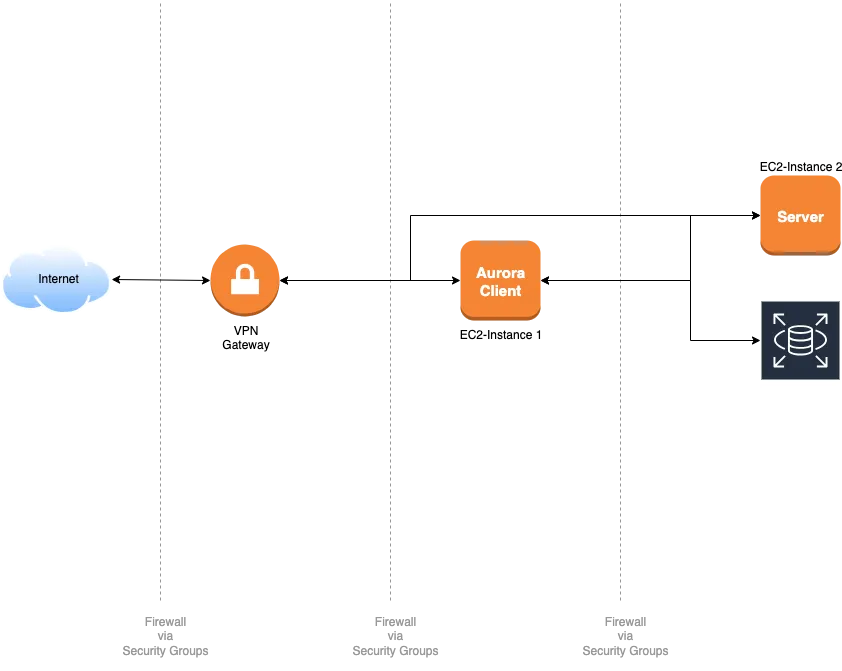
- Amazon Linux 2
- Kernel 5.10 64-bit (x86)
- Instance Type: t2.micro (1 vCPU, 1 GiB Memory)
- Storage Volume Type: SSD gp3 (16 GiB)
- Standard Network Profile (Allow SSH)
- Amazon Linux 2
- Kernel 5.10 64-bit (x86)
- Instance Type: t2.xlarge (4 vCPU, 16 GiB Memory)
- Storage Volume Type: SSD gp3 (16 GiB)
- Standard Network Profile (Allow SSH)
- Aurora Standard (MySQL compatible)
- Serverless v2, default.aurora-mysql8.0
- From 2 ACUs to 8 ACUs, autoscaling
- SSD Volume, autoscaling
Datasets
The datasets used for the benchmark are not particularly large but are sufficient to run multiple join queries. While these queries are not overly complex, they require the applications to efficiently utilise their resources, ensuring meaningful measurements for identifying key performance indicators.
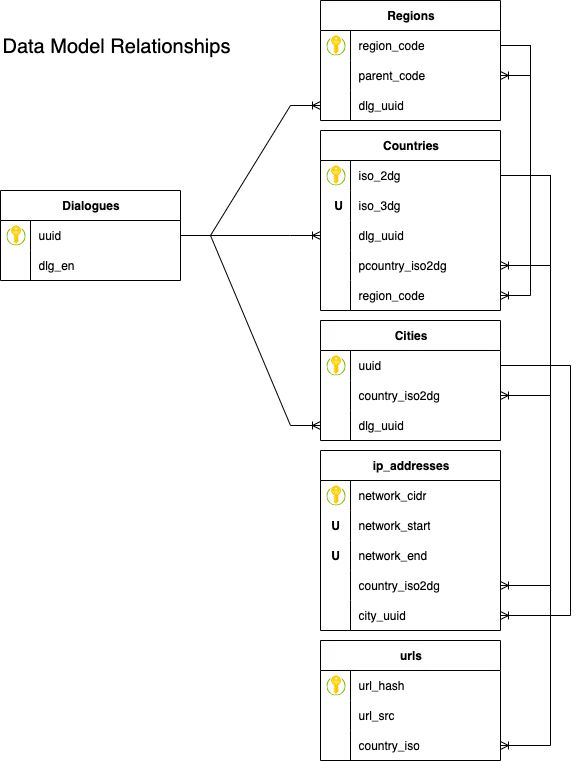
These datasets are primarily "IP geo-location" oriented and consist of the following sources:
- A list of dialogues, with location labels/names, totaling 120,668 records.
- A list of regions, containing continental positioning data, totaling 31 records.
- A list of countries, with country-level coordinates, totaling 252 records.
- A list of cities, providing location data for each place within its respective country, totaling 141,786 records.
- A list of IP addresses, serving as one geo-location source to be linked with the other datasets, totaling 4,719,740 records.
- A list of URLs, another geo-location source, to be linked with the previous data, totaling 872,238 records.
Setup
I. Client instance
- Launch & initialise the client dedicated EC2-Instance.
- When it is running, update Linux packages (sudo yum update -y).
- Install the client software packages according to the below procedure.
- Power off the instance, make a snapshot of the volume in case of, and restart it.
- Launch & initialise the server dedicated EC2-Instance.
- When it is running, update Linux packages (sudo yum update -y).
- Install AWS CloudWatch agent (sudo yum install amazon-cloudwatch-agent -y)
- Power off the instance, make a snapshot of the volume and restart it.
- Install one of the server software packages according to the below procedure.
Note: Server instance volume snapshot is useful to avoid any potential conflicts between MySQL and MariaDB software.
Once the software is configured and running, perform benchmark sequences and collect the measures. Then:
- Power off the server EC2-Instance.
- Replace the instance volume with the snapshot.
- Repeat operation from step II.4 server-side without snapshoting the volume and proceed with the next test.
It is required to allow ports 3306 (MySQL/MariaDB), with the IP version set to IPv4 and the Protocol set to TCP, in the Inbound rules.
The MySQL edition used for the benchmark is the Community Edition.
MySQL not being part of AWS Linux 2 repository, it is required to install it directly from MySQL yum repository.
Note: Although version 8.4.4 is currently published, the procedure below installs version 8.0.41, as many dependencies are "unresolved" with the latest version in the AWS Linux 2 repository. Moreover, this makes the comparison more aligned in terms of version with Aurora, since the latter provides compatibility with MySQL 8.0.39 at the time this benchmark is run.
- To avoid potential "Oracle GPG package signature failure" problem:
# Download MySQL GPG key sudo rpm --import https://repo.mysql.com/RPM-GPG-KEY-mysql-2023
- Add the MySQL yum repository:
# 1. Download the MySQL yum repo. RPM sudo wget https://dev.mysql.com/get/mysql80-community-release-el7-5.noarch.rpm # 2. Install the MySQL yum repo. sudo rpm -ivh mysql80-community-release-el7-5.noarch.rpm
- Install MySQL Community Server:
# Install MySQL Community Server and its dependencies sudo yum install mysql-server -y
- Enable & start MySQL Server service:
# 1. Enable MySQL Server service sudo systemctl enable mysqld # 2. Start MySQL Server service sudo systemctl start mysqld
- Verify that MySQL Server is running:
# Check MySQL Server service status sudo systemctl status mysqld
- Initialise the MySQL Server configuration:
Before all, it is needed to retrieve the default root password that has been randomly generated during the installation process.Now the secure configuration tool can be launched:# Retrieve temporary password generated for 'root@localhost' from MySQL Server log sudo grep 'temporary password' /var/log/mysqld.logThe following options are selected:# Start MySQL Server secure configuration tool sudo mysql_secure_installation# Start MySQL Server secure configuration tool -> Securing the MySQL server deployment. -> Enter password for user root: Enter the retrieved password -> The existing password for the user account root has expired. Please set a new password. -> New password: Enter the new password -> Re-enter new password: Confirm the new password -> Change the password for root ? ((Press y|Y for Yes, any other key for No) : y -> By default, a MySQL installation has an anonymous user, -> allowing anyone to log into MySQL without having to have -> a user account created for them. This is intended only for -> testing, and to make the installation go a bit smoother. -> You should remove them before moving into a production -> environment. -> Remove anonymous users? (Press y|Y for Yes, any other key for No) : y -> Normally, root should only be allowed to connect from -> 'localhost'. This ensures that someone cannot guess at -> the root password from the network. -> Disallow root login remotely? (Press y|Y for Yes, any other key for No) : n -> ... skipping. -> By default, MySQL comes with a database named 'test' that -> anyone can access. This is also intended only for testing, -> and should be removed before moving into a production -> environment. -> Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y -> - Dropping test database... -> Success. -> - Removing privileges on test database... -> Success. -> Reloading the privilege tables will ensure that all changes -> made so far will take effect immediately. -> Reload privilege tables now? (Press y|Y for Yes, any other key for No) : y -> Success. -> All done!Note: Despite answering N to the "Disallow root login remotely?" question, you may encounter an Access Denied error during the first remote connection with mysql client. If that happens, you will need to connect to the server locally and execute the following commands:# Solve 'access denied' issue for remote login mysql -h server_ip_address -u root -p -e "UPDATE mysql.user SET host = '%' WHERE user = 'root' AND host = 'localhost';" # Restart MySQL Server service sudo systemctl restart mysqld - It is more than likely that the MySQL server is listening on TCPIPv6 type addresses only. To verify the addresses bound by MySQL Server for listening:
If so, it is suggested to make MySQL Server also listen on TCPIPv4 type addresses to simplify connectivity from the client.# List addresses & ports MySQL Server is listening sudo ss -tulpn | grep LISTEN | grep mysqld -> tcp6 0 0 :::3306 :::* LISTEN pid/mysqld -> tcp6 0 0 :::33060 :::* LISTEN pid/mysqld
To do this, edit the MySQL Server configuration file /etc/my.cnf and add the following under the [mysqld] section:Then, it is required to restart the MySQL Server to apply the changes:[mysqld] bind-address=0.0.0.0Check again the addresses bound by MySQL Server for listening:# Restart MySQL Server service sudo systemctl restart mysqld# List addresses & ports MySQL Server is listening sudo ss -tulpn | grep LISTEN | grep mysqld -> tcp 0 0 0.0.0.0:3306 0.0.0.0:* LISTEN pid/mysqld -> tcp6 0 0 :::33060 :::* LISTEN pid/mysqld
Verify that client is able to connect to the server:
- Copy mysql_mariadb/Bench_MySQL8_DDL.sql to the server dedicated EC2-Instance.
- Copy the following 6 files to the server dedicated EC2-Instance, in the /var/lib/mysql-files/ directory:
- datasets/cities.csv
- datasets/countries.csv
- datasets/dialogues.csv
- datasets/ipaddresses.csv
- datasets/regions.csv
- datasets/urls.csv
- Change copied files ownership to ensure mysqld process is allowed to read them:
# Change dataset sources ownership chown mysql:mysql /var/lib/mysql-files/*.csv
Import the dataset sources in the following order:
- dialogues.csv
# Import 'dialogues' dataset LOAD DATA INFILE '/var/lib/mysql-files/dialogues.csv' INTO TABLE benchdb0.dialogues FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,dlg_en); -> Query OK, 120668 rows affected
- regions.csv
# Import 'regions' dataset LOAD DATA INFILE '/var/lib/mysql-files/regions.csv' INTO TABLE benchdb0.regions FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (region_code,@nparent_code,dlg_uuid) SET parent_code = NULLIF(@nparent_code, ''); -> Query OK, 31 rows affected
- countries.csv
# Import 'countries' dataset LOAD DATA INFILE '/var/lib/mysql-files/countries.csv' INTO TABLE benchdb0.countries FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (iso_2dg,iso_3dg,dlg_uuid,@npcountry_iso2dg,region_code) SET pcountry_iso2dg = NULLIF(@npcountry_iso2dg, ''); -> Query OK, 252 rows affected
- cities.csv
# Import 'cities' dataset LOAD DATA INFILE '/var/lib/mysql-files/cities.csv' INTO TABLE benchdb0.cities FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,country_iso2dg,dlg_uuid); -> Query OK, 141786 rows affected
- ipaddresses.csv
# Import 'ipaddresses' dataset LOAD DATA INFILE '/var/lib/mysql-files/ipaddresses.csv' INTO TABLE benchdb0.ipaddresses FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (network_cidr,network_start,network_end,country_iso2dg,city_uuid); -> Query OK, 4719740 rows affected
- urls.csv
# Import 'urls' dataset LOAD DATA INFILE '/var/lib/mysql-files/urls.csv' INTO TABLE benchdb0.urls FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (url_hash,url_src,country_iso); -> Query OK, 872238 rows affected
The MariaDB edition used for the benchmark is the Community Edition.
Since MariaDB is part of the AWS Linux 2 repository, it should be easy to install it from AWS Linux 2 yum repository. However, the latest version available in the AWS Linux 2 repository is MariaDB 5.5.68, so it is required to tweak the MariaDB yum repo. configuration to get a more recent release.
Note: Although version 11.7.2 is currently published, the procedure below installs version 11.6.1, as it is the latest version available for AWS Linux 2, which is thought to have an underlying operating system based on CentOS 7.
- Edit the MariaDB yum repository by either replacing the entire content of the configuration file or adding to it with the following:
# Create/Edit /etc/yum.repos.d/MariaDB.repo [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/11.rc/centos7-amd64 gpgkey = https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1
- Install MariaDB Community Server:
# Install MariaDB Community Server and its dependencies sudo yum install mariadb-server -y
- Enable & start MariaDB Server service:
# 1. Enable MariaDB Server service sudo systemctl enable mariadb # 2. Start MariaDB Server service sudo systemctl start mariadb
- Verify that MariaDB Server is running:
# Check MariaDB Server service status sudo systemctl status mariadb
- Initialise the MariaDB Server configuration:
When MariaDB Server is installed, there is no root password defined, it is then required to set it.Once locally connected to the server, execute the following 3 commands:# Connect to local MariaDB Server sudo mariadb -u rootRestart the server:# Clean up unused DELETE FROM mysql.user WHERE host <> 'localhost' OR TRIM(user) = ''; -> Query OK, 5 rows affected (0.000 sec) # Set root password SET PASSWORD = PASSWORD('your_password'); -> Query OK, 0 rows affected (0.000 sec) # Allow remote login UPDATE mysql.user SET host = '%' WHERE user = 'root' AND host = 'localhost'; -> Query OK, 1 row affected (0.000 sec)# Restart MariaDB Server service sudo systemctl restart mariadb
- Install MariaDB Community Client:
# Install MariaDDB Community Client and its dependencies sudo yum install mariadb -y
- Verify that client is able to connect to the server dedicated instance:
# Connect MariaDB Server instance mariadb -h host_ipv4_address -u root -p
- Copy mysql_mariadb/Bench_MySQL8_DDL.sql to the client dedicated EC2-Instance.
- Copy the following 6 files to the client dedicated wherever you want as long as they are accessible from MariaDB Client, and to the server dedicated EC2-Instances, in the /var/lib/mysql/ directory:
- datasets/cities.csv
- datasets/countries.csv
- datasets/dialogues.csv
- datasets/ipaddresses.csv
- datasets/regions.csv
- datasets/urls.csv
Import the dataset sources in the following order:
- dialogues.csv
# Import 'dialogues' dataset LOAD DATA INFILE '/var/lib/mysql/dialogues.csv' INTO TABLE benchdb0.dialogues FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,dlg_en); -> Query OK, 120668 rows affected
- regions.csv
# Import 'regions' dataset LOAD DATA INFILE '/var/lib/mysql/regions.csv' INTO TABLE benchdb0.regions FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (region_code,@nparent_code,dlg_uuid) SET parent_code = NULLIF(@nparent_code, ''); -> Query OK, 31 rows affected
- countries.csv
# Import 'countries' dataset LOAD DATA INFILE '/var/lib/mysql/countries.csv' INTO TABLE benchdb0.countries FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (iso_2dg,iso_3dg,dlg_uuid,@npcountry_iso2dg,region_code) SET pcountry_iso2dg = NULLIF(@npcountry_iso2dg, ''); -> Query OK, 252 rows affected
- cities.csv
# Import 'cities' dataset LOAD DATA INFILE '/var/lib/mysql/cities.csv' INTO TABLE benchdb0.cities FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,country_iso2dg,dlg_uuid); -> Query OK, 141786 rows affected
- ipaddresses.csv
# Import 'ipaddresses' dataset LOAD DATA INFILE '/var/lib/mysql/ipaddresses.csv' INTO TABLE benchdb0.ipaddresses FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (network_cidr,network_start,network_end,country_iso2dg,city_uuid); -> Query OK, 4719740 rows affected
- urls.csv
# Import 'urls' dataset LOAD DATA INFILE '/var/lib/mysql/urls.csv' INTO TABLE benchdb0.urls FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (url_hash,url_src,country_iso); -> Query OK, 872238 rows affected
To start setting up Aurora (MySQL compatible), you have to connect to your AWS RDS Console.
- Select the Databases menu and click on Create database button. Then:
- Select Standard create as Database creation method option.
- Select Aurora (MySQL compatible) as Engine type option.
- Select Aurora MySQL 3.08.2 (compatible with MySQL 8.0.39) as Engine version option, which is currently the latest one.
- Select Dev/Test as Template option.
- Optionally, change the default name of the cluster identifier.
- Carefully set your Master username. This user is the database server's primary user which compulsorily replaces the default MySQL/MariaDB root user.
- Select Self managed as Credentials management option and define carefully your password.
- Select Aurora standard as Configuration option.
- Select Serverless v2 as DB instance class option.
- Set 2 ACUs as Minimum capacity and 8 ACUs as Maximum capacity options. The reason is that it is not possible to precisely define the number of CPUs and memory separately in this type of configuration. That said, by specifying the proposed values ranging from 2 to 8 ACUs, Aurora starts with approximately the equivalent of 4 CPUs and 4 GiB of memory, and automatically scales up to a maximum of 16 CPUs and 16 GiB of memory in case of load increase; this allows for a configuration that closely matches the other tested technologies.
- Select Don't create an Aurora Replica as Multi-AZ deployment option. It is useless to configure a full replicated cluster in current benchmark context.
- Select Don't connect to an EC2 compute resource as Compute resource option.
- Select IPv4 as Network type option.
- Select the VPC and the DB subnet group according to the ones where your client dedicated EC2-Instances reside.
- Select No as Public access option.
- Select Choose existing as VPC security group option and select the Security Group you previously defined.
- Select the Availability zone according to the ones where your client dedicated EC2-Instances reside.
- Uncheck the RDS Proxy checkbox.
- Uncheck the Enable Performance insights checkbox.
- Check the Enhanced Monitoring checkbox, select 60 seconds and select default as respectively OS metrics granularity and Monitoring role for OS metrics options.
- Check the Error Log checkbox as Log exports option.
- Leave all other options at their default settings.
- Review the various settings and click on Create database button underneath.
- Once the Aurora instance is created, it is necessary to collect both the Reader and the Writer endpoints in order to be able to connect them with the client applications.
If you followed the order of the technologies presented here, Aurora being based on MariaDB, the client dedicated installation can be retained and thus reused.
Since RDS doesn't allow access to the underlying system, the files must be uploaded from client application.
It is therefore recommended to ensure that the server allows local file upload:
Import the dataset sources in the following order:
- dialogues.csv
# Import 'dialogues' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/dialogues.csv' INTO TABLE benchdb0.dialogues FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,dlg_en); -> Query OK, 120668 rows affected
- regions.csv
# Import 'regions' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/regions.csv' INTO TABLE benchdb0.regions FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (region_code,@nparent_code,dlg_uuid) SET parent_code = NULLIF(@nparent_code, ''); -> Query OK, 31 rows affected
- countries.csv
# Import 'countries' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/countries.csv' INTO TABLE benchdb0.countries FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (iso_2dg,iso_3dg,dlg_uuid,@npcountry_iso2dg,region_code) SET pcountry_iso2dg = NULLIF(@npcountry_iso2dg, ''); -> Query OK, 252 rows affected
- cities.csv
# Import 'cities' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/cities.csv' INTO TABLE benchdb0.cities FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (uuid,country_iso2dg,dlg_uuid); -> Query OK, 141786 rows affected
- ipaddresses.csv
# Import 'ipaddresses' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/ipaddresses.csv' INTO TABLE benchdb0.ipaddresses FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (network_cidr,network_start,network_end,country_iso2dg,city_uuid); -> Query OK, 4719740 rows affected
- urls.csv
# Import 'urls' dataset LOAD DATA LOCAL INFILE 'path_to_uploaded_file/urls.csv' INTO TABLE benchdb0.urls FIELDS TERMINATED BY ',' ENCLOSED BY '"' LINES TERMINATED BY '\n' IGNORE 1 ROWS (url_hash,url_src,country_iso); -> Query OK, 872238 rows affected
Currently, there's no official repository yet for the Flexway packages distribution, it is therefore needed to download and install the corresponding RPM manually.
- Copy fw/Bench_FW_DDL.sql to the server dedicated EC2-Instance.
- Copy the following 6 files to the server dedicated EC2-Instance, wherever you want as long as they are accessible from the CLI:
- datasets/cities.sql
- datasets/countries.sql
- datasets/dialogues.sql
- datasets/ipaddresses.sql
- datasets/regions.sql
- datasets/urls.sql
Import the dataset sources in the following order:
- dialogues.sql
# Import 'dialogues' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/dialogues.sql
- regions.csv
# Import 'regions' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/regions.sql
- countries.csv
# Import 'countries' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/countries.sql
- cities.csv
# Import 'cities' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/cities.sql
- ipaddresses.csv
# Import 'ipaddresses' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/ipaddresses.sql
- urls.csv
# Import 'urls' dataset fwtsmcli -w benchmark.fwts < path_to_uploaded_file/urls.sql
Test Sequences
To execute the test sequences below, it is necessary to connect to the various EC2-instances via SSH. This obviously assumes that the applications involving the technology to test are up and running.
Note:
Lookup Query 1
Lookup Query 2
Lookup Query 3
Lookup Query 4
Server CPU Utilisation Peak
Using AWS CloudWatch, determine what is the server dedicated EC2-Instance CPU Utilisation Peak. As only MySQL server is running on the virtual machine, the EC2.CPUUtilisation metric can be reliably collected.
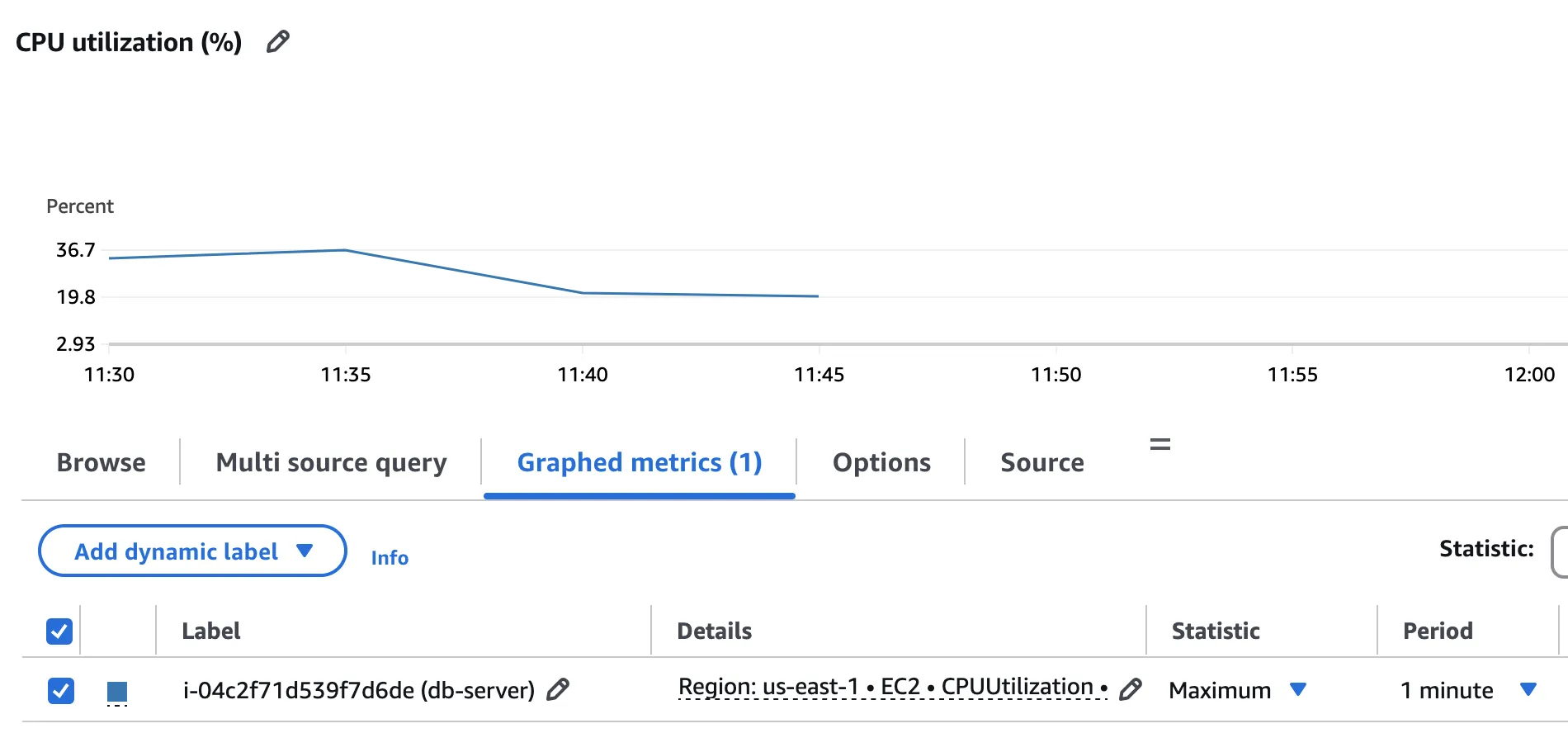
According to the above graph, the CPU usage peak reaches 36.7%.
Lookup Query 1
Lookup Query 2
Lookup Query 3
Lookup Query 4
Server CPU Utilisation Peak
Using AWS CloudWatch, determine what is the server dedicated EC2-Instance CPU Utilisation Peak. As only MariaDB server is running on the virtual machine, the EC2.CPUUtilisation metric can be reliably collected.
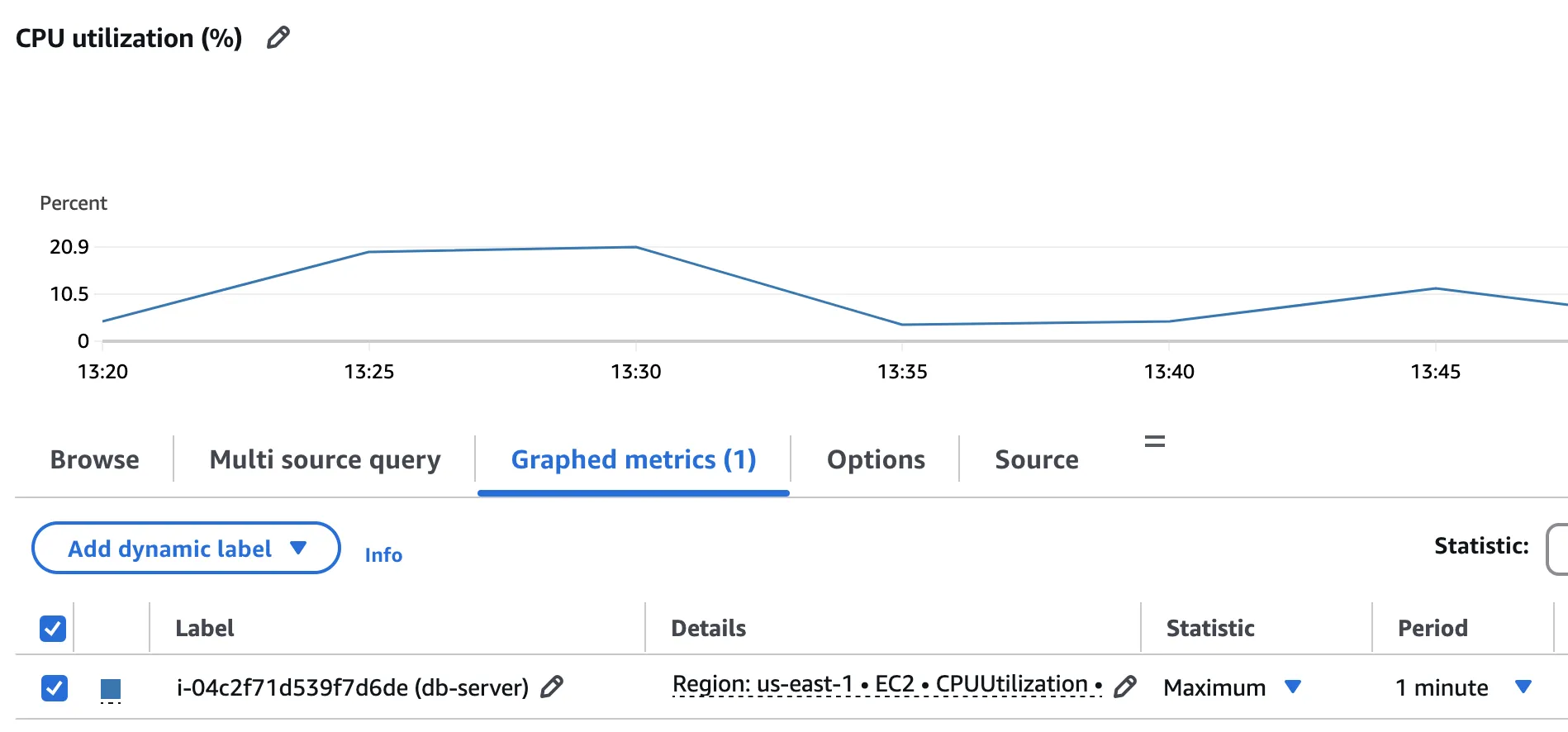
According to the above graph, the CPU usage peak reaches 20.9%.
Lookup Query 1
Lookup Query 2
Lookup Query 3
Lookup Query 4
Server ACU & CPU Utilisation Peaks
Using AWS CloudWatch, determine what are the Aurora-Instance ACU & CPU Utilisation Peaks.
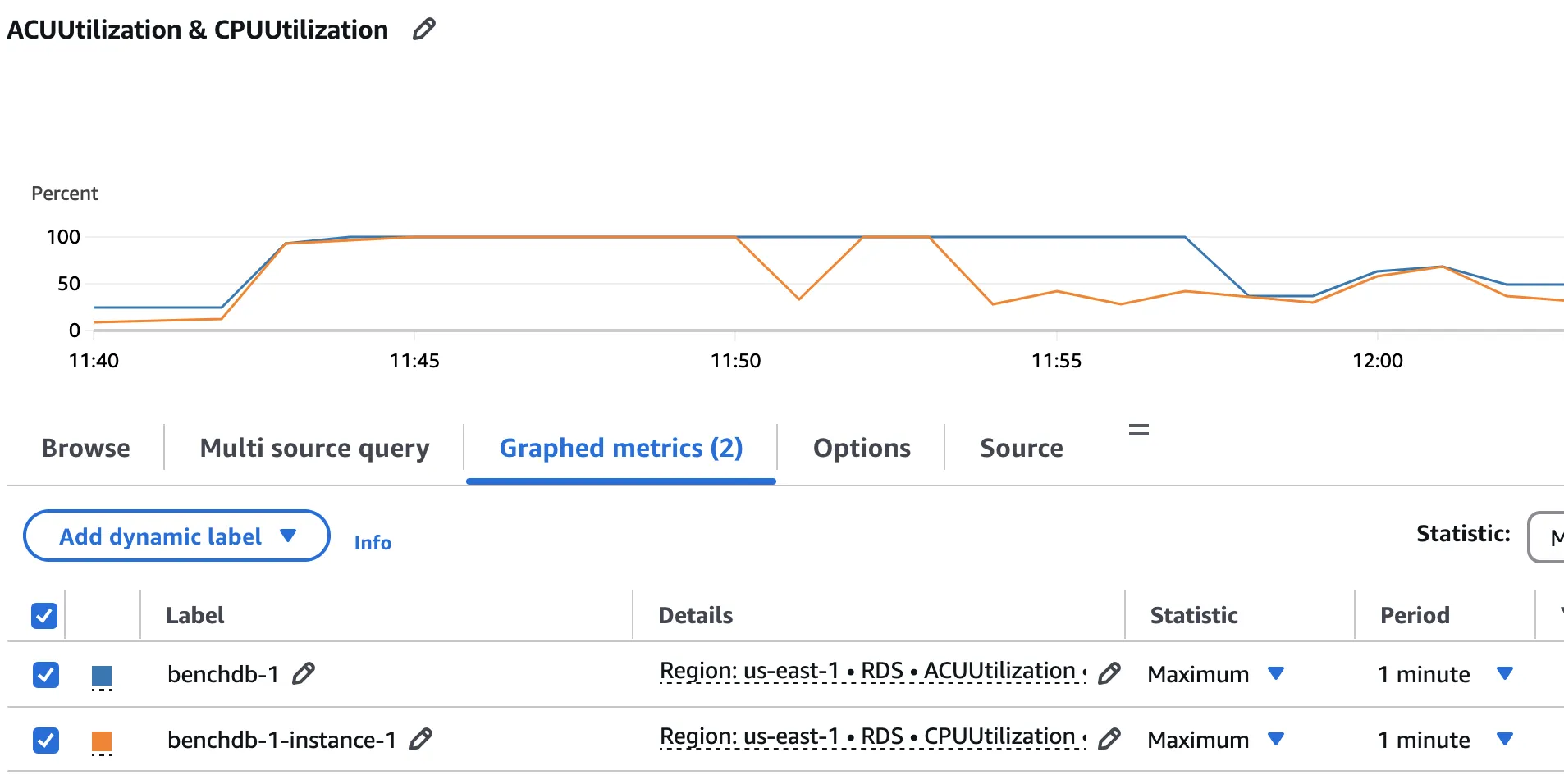
According to the above graph, the instance's CPU peaks reach 100% utilisation, both in terms of ACU and raw CPU usage.
Connect benchmark tablespace in read-only mode
Lookup Query 1
Lookup Query 2
Lookup Query 3
Lookup Query 4
Server CPU Utilisation Peak
Using AWS CloudWatch, determine what is the server dedicated EC2-Instance CPU Utilisation Peak. As only DBS server is running on the virtual machine, the EC2.CPUUtilisation metric can be reliably collected.

According to the above graph, the CPU usage peak reaches 16.5%.
Benchmark Metrics Summary
The following table summarises the results from the benchmark test sequences across the various technologies tested:
| Test Sequence | MySQL | MariaDB | Aurora | Flexway |
|---|---|---|---|---|
| Lookup Query 1 (Seconds) | 1.070 | 15.446 | 1.940 | 0.248 |
| Lookup Query 2 (Seconds) | 60.320 | 151.558 | 74.870 | 0.121 |
| Lookup Query 3 (Seconds) | 7.010 | 14.225 | 0.543 | 0.279 |
| Lookup Query 4 (Seconds) | 1.780 | 55.434 | 5.769 | 0.341 |
| Max. CPU Peak | 36.7% | 20.9% | 100.0% | 16.5% |
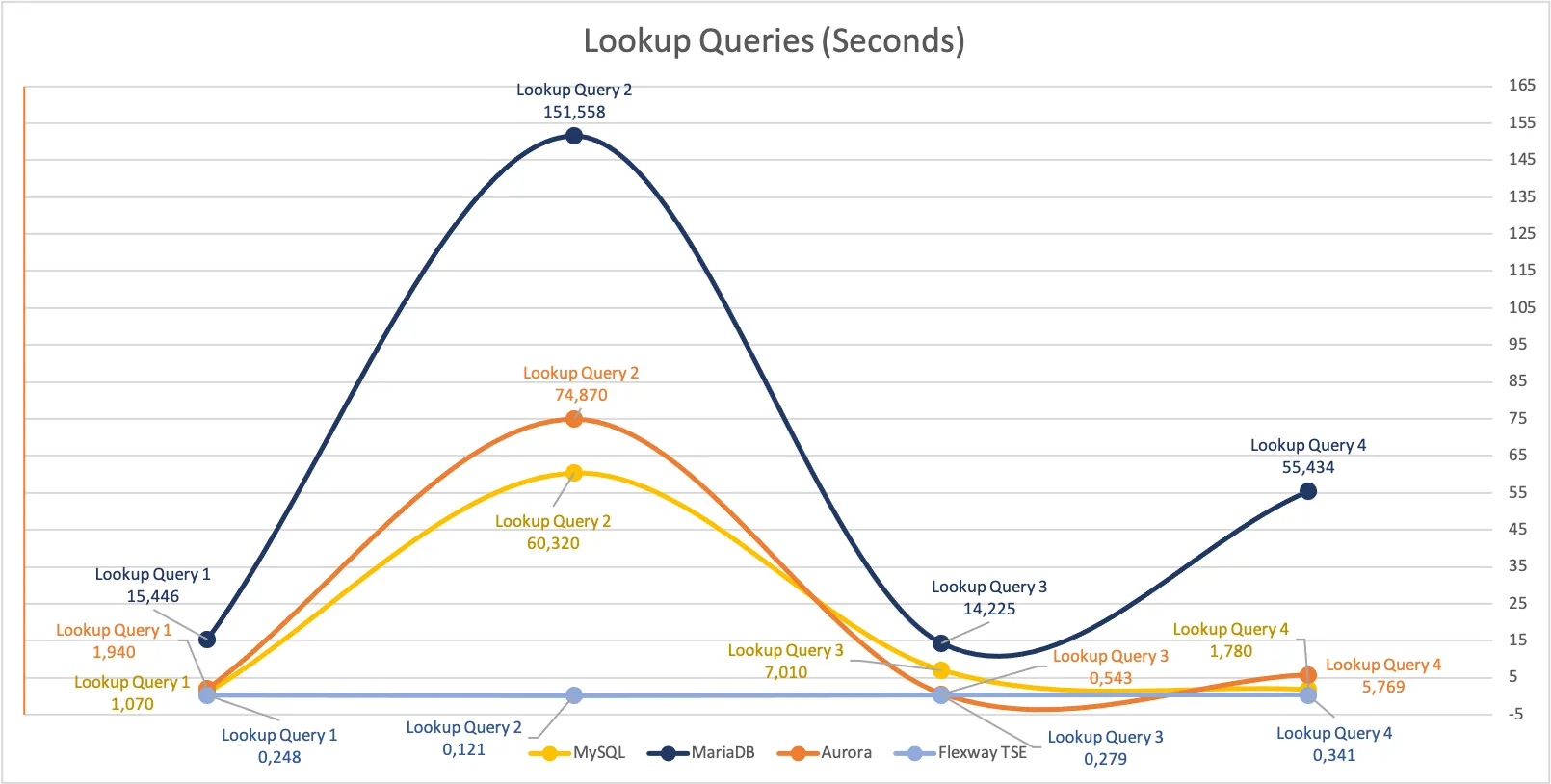
Conclusion
Although Flexway Tablespace-Engine is still in a building phase, it stands up well when compared to established and well-known RDBMS like MySQL, MariaDB, and Aurora. On the contrary, the benchmark results tell a different story: on average, Flexway Tablespace-Engine is extremely much faster than the tested alternatives.
It's worth noting, however, that development of Flexway Tablespace-Engine has primarily focused on optimising for lookup queries, which is clearly reflected in the results. That said, an area of improvement has been identified in handling concurrent write I/O operations (A limitation that will be addressed in future versions).
When considering Green IT, a crucial and increasingly important topic, Flexway Tablespace-Engine also shines. It is able to deliver better performance than the alternatives while consuming fewer resources (CPU peak). This lower resource consumption translates into reduced system requirements, which in turn leads to lower energy consumption and operational costs.
Looking ahead, Flexway development team will continue to focus on enhancing its capabilities.